Rat-SLAM阅读笔记
2018-09-05
如果是关心我博客的朋友可能会发现之前放的“文献阅读”标签已经悄悄地被我下线了,因为我发现我不是一个勤快的人,不会常常关心文献。我决定以后看一个比较成体系的架构之后再稍微整理下写一篇大的。今天这篇就是这个新坑的第一篇文章——让我来谈谈对于Rat-SLAM的理解。
之所以要去看Rat-SLAM,是因为之前综合CMP、Rat-SLAM、Reinforcement learning胡乱写的自然基金居然中了……也不知道是个好事还是坏事,总之可能之后的博士生涯就是和这个玩意儿做斗争了。
一、Why Rat-SLAM
机器人科学家长期以来一直梦想着给机器人创造类似的导航技能。 为了让机器人能够在我们的环境中变得更有用,机器人就必须具备在周围环境中靠自己寻路的能力。 有些机器人已经在家庭、办公室、仓库、医院、酒店以及自驾车,甚至整个城市范围内的环境中正在学习找路。尽管如此,这些机器人平台仍然难以在轻微挑战的条件下可靠地运行。 例如,自主驾驶车辆可能配备了复杂的传感器和前方道路的精细地图,但是司机仍然需要在大雨或下雪或夜间进行控制。
为了使机器人具有自主的导航功能,人们自然地将这个大问题切分成为两个子问题:“地图构建”&“导航”。为了完成这两个任务,我们要求机器人具备以下关键能力:探索未知环境、同步定位与建图(SLAM)、目标导航的路径规划与执行、环境变化的适应性。到目前为止,对于以上问题最成功的解决方案是基于核心概率法,使用大量从距离到拓扑的地图表征方法。这些基于概率的方法有很好的SLAM性能,但是很少能够完全解决整个地图构建与导航问题。相比之下,生物系统鲜为人知,并且仿真计算模型在恶劣环境下机器人平台上的应用非常有限。然而一个基本事实是:许多动物在不具备高精度传感器和高分辨率地图的情况下也能够很好地解决整个SLAM问题。Rat-SLAM是受生物启发的SLAM系统,它仿真老鼠的海马体,构建了一套SLAM与导航系统,给出了另一条解决问题的研究思路————基于生物机制去解决导航问题。
二、Rat-SLAM的工作机制
1.一些生物学的概念
位置细胞:小鼠在一个特定的位置会被激活,在其他的地点处于抑制状态;(海马体)

头朝向细胞:当小鼠处于一个朝向时被激活其他朝向时被抑制;(海马体)

- 网格细胞:在内嗅皮层中的网格细胞是早于Rat-SLAM而在最近被发现的。它呈现六边形的结构,并且对空间进行编码,当小鼠处于空间中不同的位置时细胞放电的模式不同,以实现对空间的编码。令人感到有趣的是,RatSLAM在不知道到网格细胞存在的情况下,设计的小鼠海马体模型,得到了与网格细胞相似的放电结果;(内嗅皮层)

2.RatSLAM架构
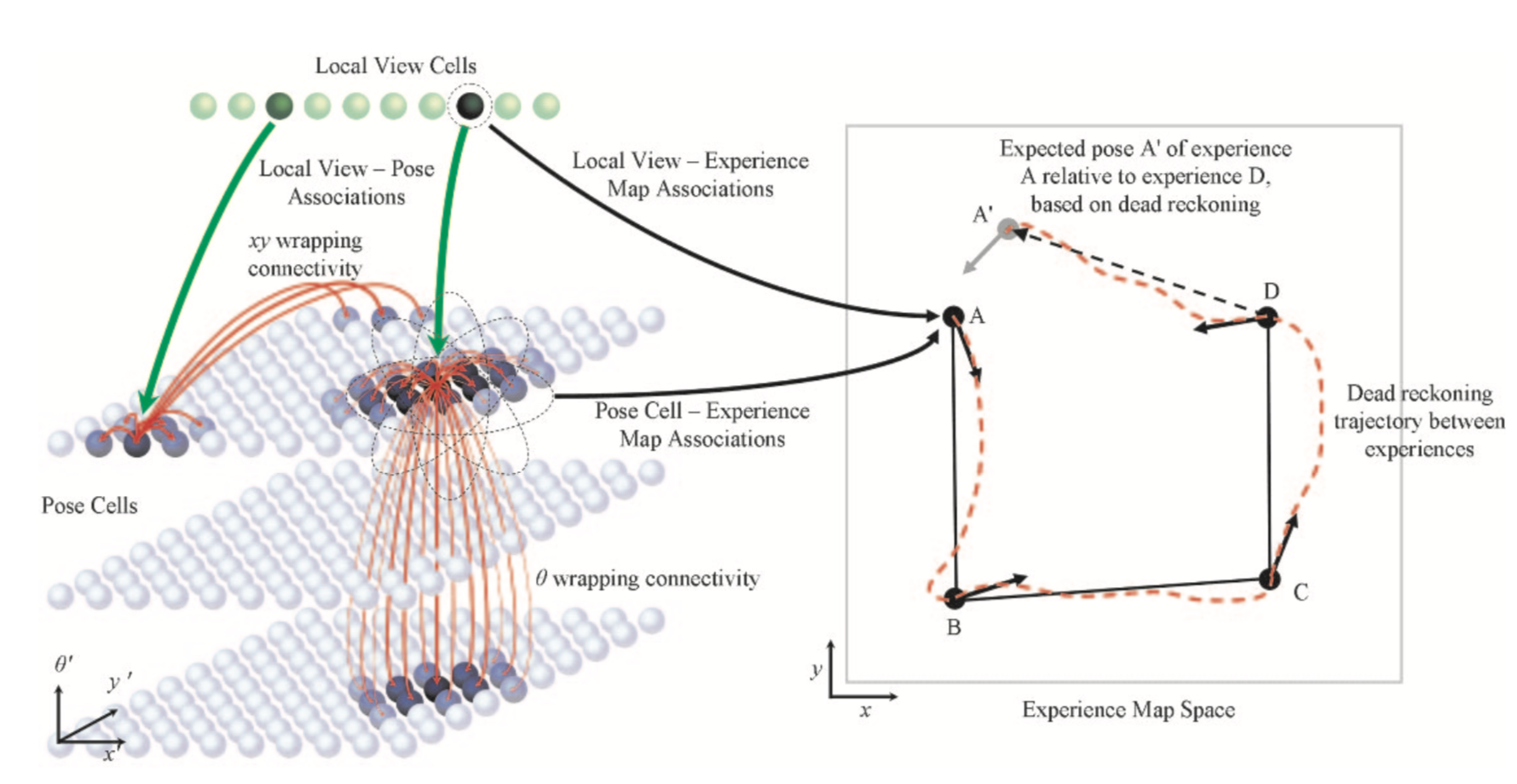
RatSLAM的核心架构分为两部分:PosCell 与 Experience Map。其中PoseCell是核心部分,是对位置细胞和头朝向细胞的建模,其实现效果与网格细胞十分的类似,现在我将分别对PosCell与Experience Map作简要的介绍。
2.1 PoseCell:

PoseCell是文章的核心创新点,如上图所示,PoseCell被建模为一个连续吸引网络(Continuous attractor networks),其可以被三种方式更新:Attractor Dynamics、 Path Integration、 Local View Calibration。
2.1.1 Attractor Dynamics
Attractor Dynamics分为两种机制:对附近细胞的激活、对其他所有细胞的抑制。这样做的好处在于,如果机器人没有运动,那么随着时间的进行AD机制会式细胞的激活模式稳定下来。AD机制具体的数学实现如下。对于周围细胞的激活与抑制机制,都使用三维高斯分布完成的。
- 激活:细胞对周围细胞的激活机制可以变相地理解为细胞接受来自其他细胞的能量。在这个意义上我们可以认为一个细胞的能量扩散机制是与距离成反比的,在这个假设上我们设计以下的激活算法:
其中:
量度两个细胞的距离有了这个参数之后我们便可以实现我们之前的Idea。则激活机制细胞能量的改变值为:
$$\varDelta P_{x,y,z} = \sum_i^{n_x-1} \sum_j^{n_y-1} \sum_k^{nz-1} P\varepsilon$$
- 抑制:细胞对周围细胞的抑制机制可以用类似的更新机制来阐述
2.1.2 Path Integration
如上述所说,再经过了Attractor Dynamics步骤之后我们解决了第一个问题,随着时间的进行,机器人的pose会逐渐收敛下来。但是,这样的结果在于机器人的Pose细胞的pattern不会移动,为了使它动起来,我们需要引入Path Integration机制。在实现上Path Integration是一个VO,其输出的位移和角度值能够直接作用于Pose细胞,其机理也很简单,角度的改变导致了沿着纵轴的移动,xy的改变代表着沿着平面的移动。
2.1.3 Local View Calibration
再有了上述两种机制之后,我们的PoseCell便能够有放电方式的不同了。在这个基础上我们还需要做一个事情:Relocalization,即回环。在这个要求下,我们引入了Local View Calibration机制。首先我们定义一个向量V以代表不同View Cell的激活情况,然后引入矩阵以代表V向量与P矩阵的连接。遵从Hebb’s机制,我们有了下述的跟新方式:
2.2 Experience Map:
Experience Map实际上并不是和生物学有关的概念了,它在一定程度上是一个妥协的产物——向导航算法妥协。
首先一个Experience被定义为一个3-tuple
再定义一个Score Fuction,当时一个新的Experience便会被建立。
新的Experience与前一帧的关系为:
在回环方面,Experience Map的回环是依靠PoseCell的Local View Calibration机制完成的,当一个经历的P与V与已有经历的P与V相匹配时,Experience Map 开始一次回环操作,其更新的步骤为:
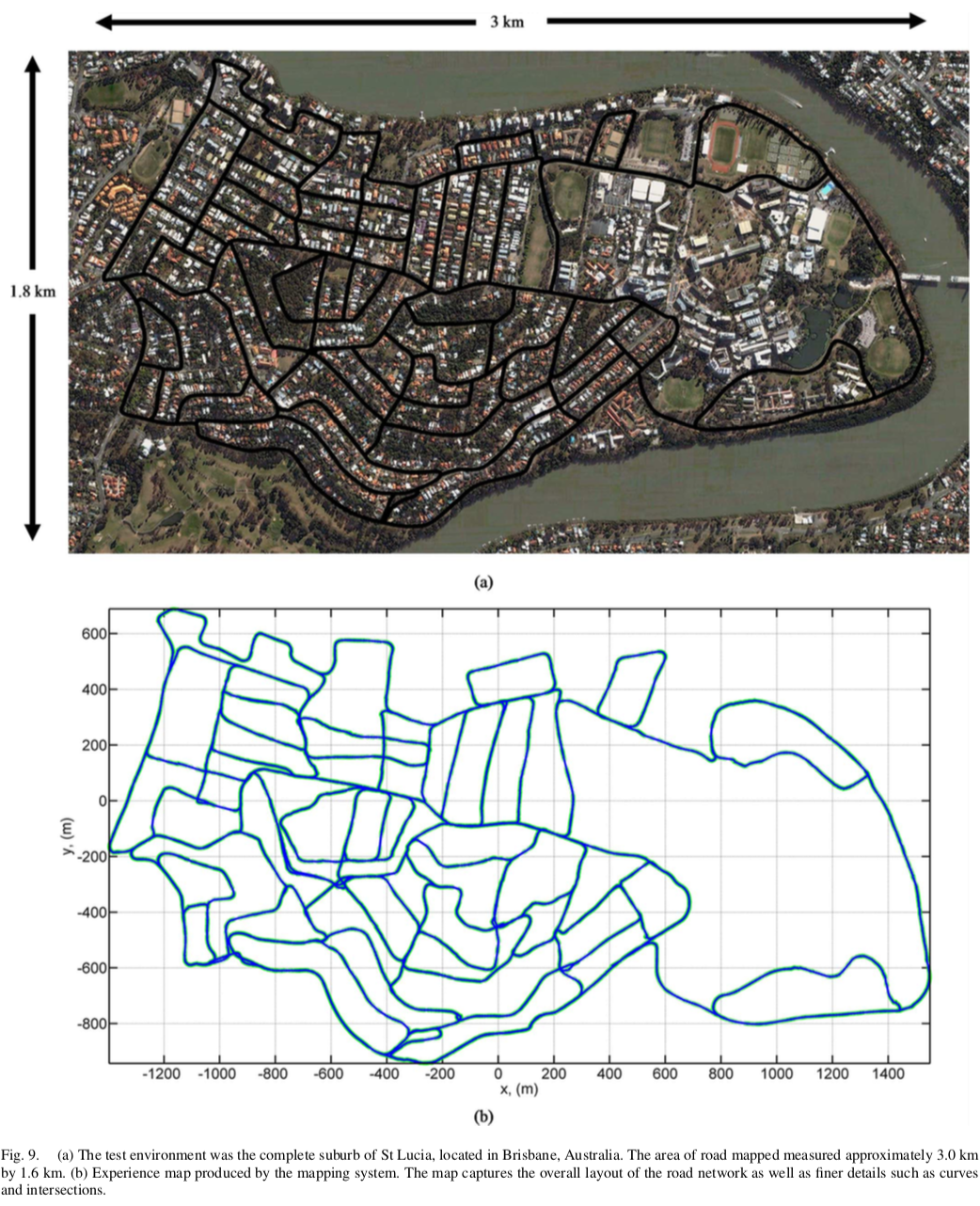
2.3 实验结果:
利用以上的架构,在一个Mac上利用其自带的相机实现了对街区的建模。在这里给出实际的建图效果,具体实验数据分析可以参考论文。